Introduction and History
Why Deep Learning?
Deep learning became important when machine learning started facing data that was too rich to be handled comfortably with handcrafted features alone. Images, audio, and language all contain high-dimensional patterns, local structure, and nonlinear relationships that are hard to summarize manually.
The core promise of deep learning is simple:
instead of designing every feature ourselves, we let the model learn useful representations directly from raw or weakly processed data.
This is why deep learning became especially strong in areas such as:
- image classification,
- speech recognition,
- natural language processing,
- segmentation and generation tasks.
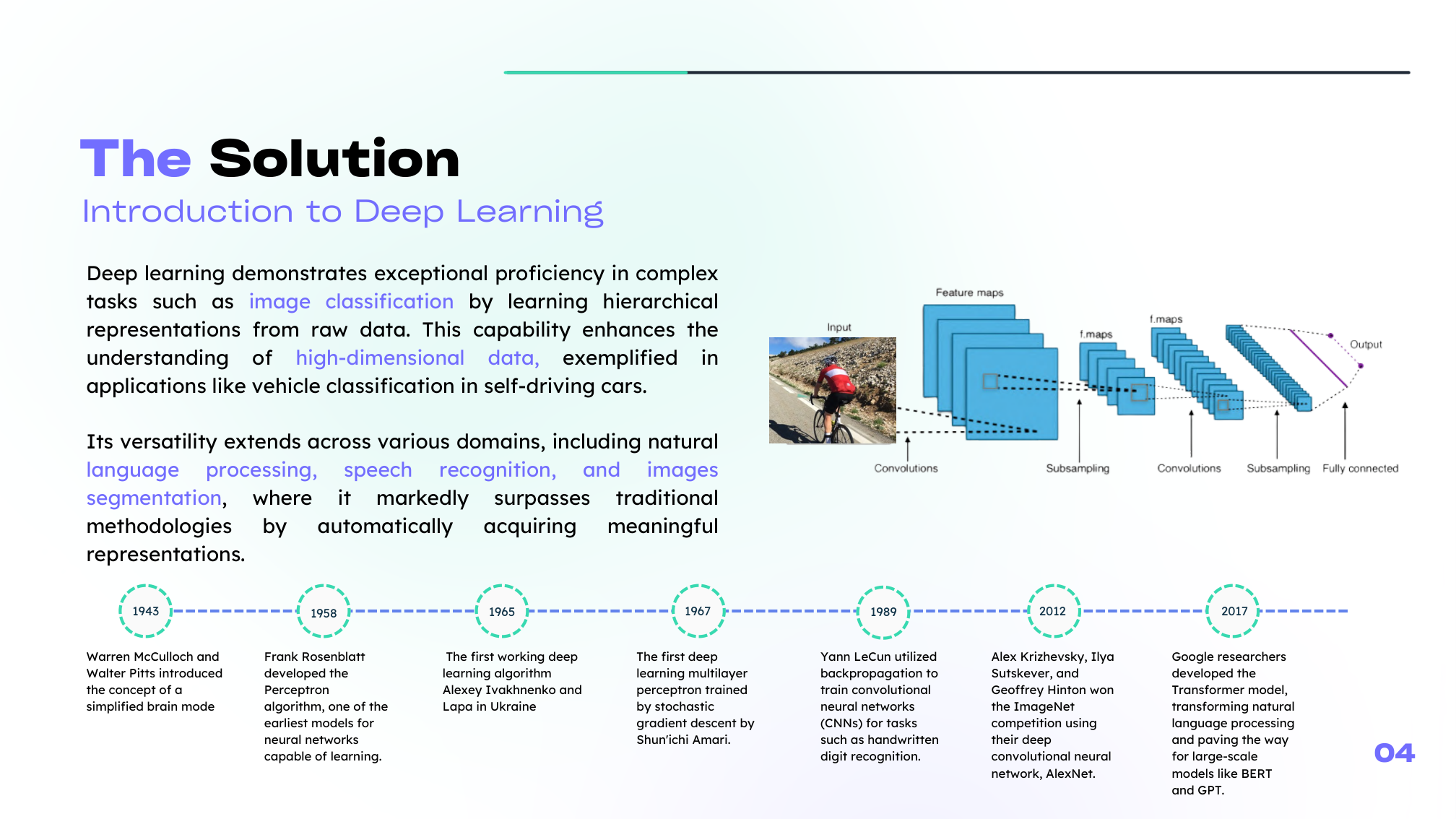
A Motivating Example: Image Classification
A useful way to see the need for deep learning is to think about image classification for autonomous vehicles. A model must distinguish bicycles, motorcycles, buses, and cars under changing angles, lighting conditions, and backgrounds.
Classical linear models struggle here because:
- the raw input is extremely high-dimensional,
- useful visual cues are often nonlinear,
- and manual feature engineering becomes fragile very quickly.
Deep learning handles this more naturally by learning hierarchical features, from simple patterns to more semantic ones.
Why It Works Today
Deep learning is not just an old idea that suddenly became fashionable. It became practical because three conditions improved at the same time:
- Data: we now have far more digital data than before.
- Compute: GPUs and specialized hardware made large-scale training feasible.
- Algorithms: backpropagation, ReLU-style activations, better initialization, and later attention-based methods made training stable enough to matter.

Main Families of Deep Learning Models
The deep-learning landscape is broad, but the foundations usually begin with a few key families:
- fully connected neural networks for general function approximation,
- CNNs for images and spatial data,
- sequence models such as RNNs and LSTMs for temporal structure,
- transformers for attention-based sequence modeling,
- generative models such as GANs and diffusion models.
In this section, we will focus on the part of the course that is fully developed in your source material: neural-network foundations and CNNs.
Summary
In this lesson we covered:
- Why deep learning matters for complex, high-dimensional data
- Why feature learning often beats handcrafted features on unstructured tasks
- The historical milestones that shaped modern deep learning
- The three practical enablers: data, compute, and better algorithms
- The main architecture families in the wider deep-learning landscape
Next: We start from the smallest possible neural model: the perceptron and the single logistic neuron.