Foundations of Model Evaluation
Why Evaluation Deserves Its Own Lesson
Training a model is only half of the work. We also need to know:
- whether the model generalizes to unseen data,
- whether its errors are acceptable for the task,
- and whether our evaluation procedure is itself trustworthy.
That is why model evaluation sits at the center of machine learning, not at the end of it.
Training, Validation, and Test Sets
The standard workflow separates data into three roles:
- Training set: used to fit model parameters.
- Validation set: used to compare settings, features, or hyperparameters.
- Test set: used once at the end for the final estimate of performance.
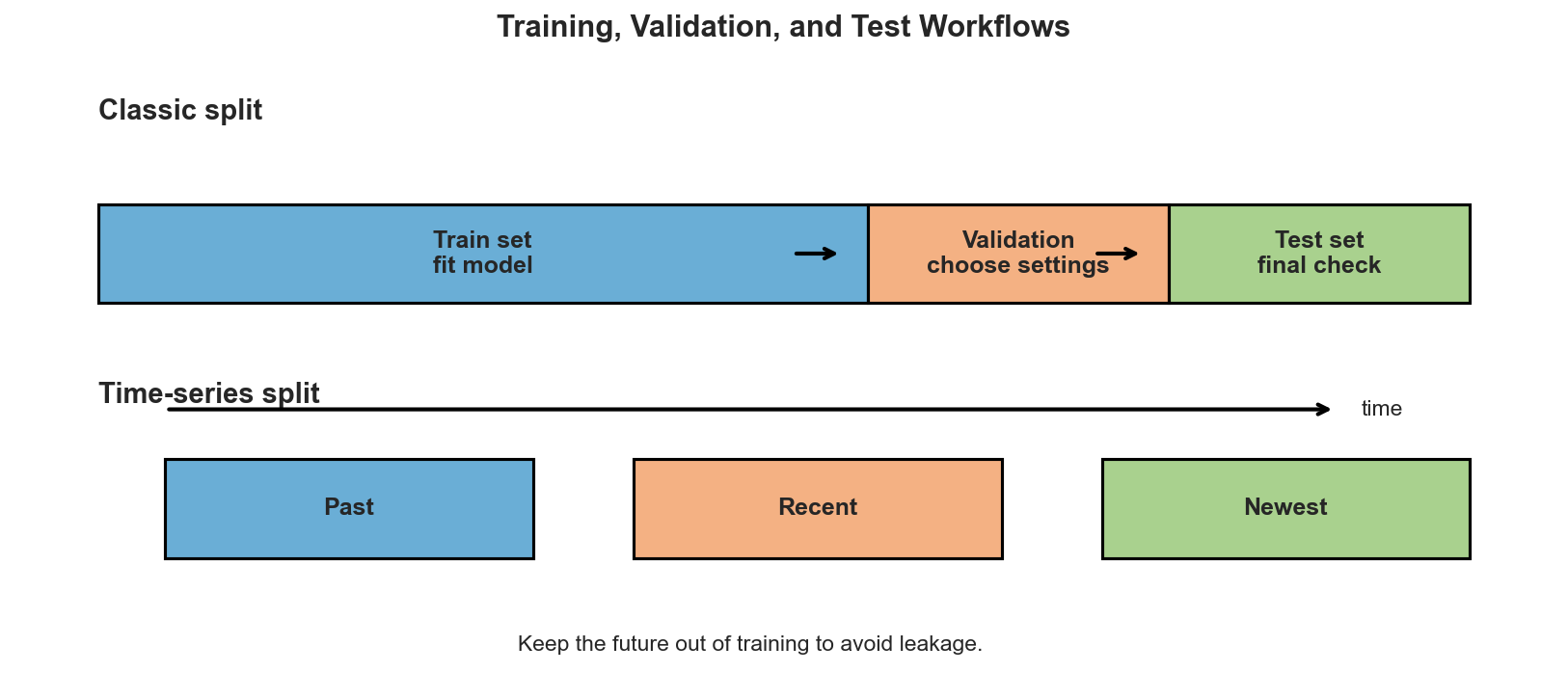
The exact proportions depend on the size of the dataset, but the principle stays the same: data used to make decisions about the model cannot also be the data used to claim final performance.
For time-series data, the split must respect chronology. Future observations should never leak into the training set.
Bias, Variance, and the Main Trade-off
Two failure modes appear again and again:
- High bias: the model is too simple and underfits.
- High variance: the model is too flexible and overfits.
The goal is not to maximize flexibility at all costs. The goal is to find the level of complexity that captures signal while staying stable on new data.
Learning Curves
Learning curves help us diagnose what is happening during training and validation.
1. Model Complexity
As complexity increases, training error usually decreases. Validation error often decreases first, then rises once overfitting begins.
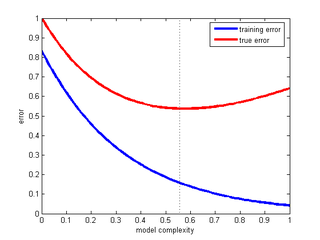
This curve is a quick way to spot underfitting versus overfitting.
2. Training Set Size
Adding more data often reduces variance and narrows the gap between training and validation performance.
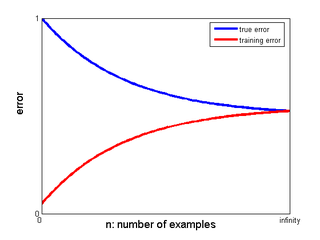
If the validation curve is still improving as data grows, collecting more observations may help more than tuning another parameter.
3. Optimization Curves
For iterative models, another useful curve tracks the objective function or validation loss over epochs or iterations. It tells us whether the optimizer is converging, plateauing, or drifting into overfitting.
Avoiding Data Leakage
A clean metric can still be misleading if information leaks across splits. Common leakage sources include:
- scaling or imputing before the split,
- selecting features using the full dataset,
- peeking at test performance while tuning,
- using future information in time-series problems.
When in doubt, remember the rule:
Every preprocessing step that learns from data must be fit on the training portion only.
Summary
In this lesson we covered:
- Why evaluation is essential for trustworthy machine learning
- The different roles of training, validation, and test sets
- The bias-variance trade-off
- How learning curves reveal underfitting and overfitting
- Why leakage can invalidate an otherwise polished experiment
Next: We will compare the most useful metrics for regression, classification, and ranking problems.