Cross-Validation Strategies
Why One Split Is Not Enough
A single train/test split can be noisy, especially when the dataset is small. The result may depend too much on which observations happened to land in the test set.
Cross-validation reduces that instability by repeating the training/validation cycle across several partitions of the data.
k-Fold Cross-Validation
In k-fold cross-validation, we divide the data into \(k\) folds:
- train on \(k-1\) folds,
- validate on the remaining fold,
- repeat until every fold has been used once for validation.
The average performance is
\[ \mathrm{CV} = \frac{1}{k}\sum_{i=1}^{k} M_i, \]where \(M_i\) is the metric computed on fold \(i\).
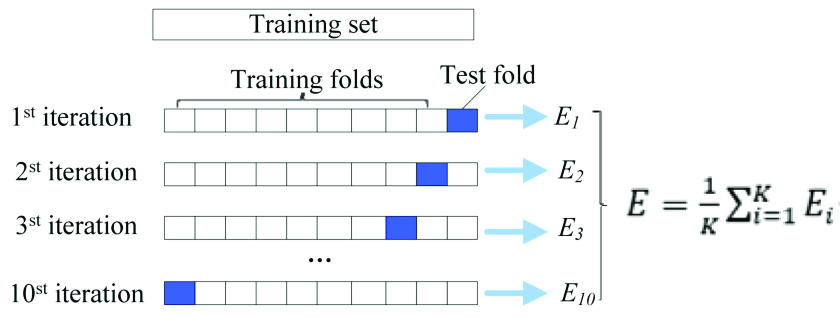
Typical choices are \(k=5\) or \(k=10\). They usually balance bias, variance, and computation well.
Leave-One-Out Cross-Validation
LOOCV is the extreme case where \(k=n\). Each iteration leaves out one observation for validation.
It has two main properties:
- it uses almost all available data for training each time,
- but it can be computationally expensive and sometimes high-variance.
LOOCV is most useful when the dataset is small and the model is cheap to fit.
Stratified Cross-Validation
For imbalanced classification, standard k-fold can produce folds with unstable class proportions. Stratified k-fold keeps the class balance of each fold close to the full dataset.
That makes evaluation more reliable when one class is rare.
Time-Series Cross-Validation
Time-dependent data requires a different strategy. We must preserve order:
- train on the past,
- validate on a later period,
- then roll or expand the window forward.
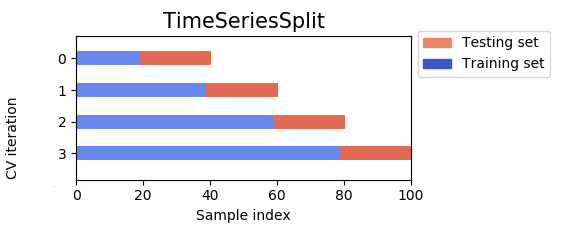
This avoids one of the most serious forms of leakage: using future information to predict the past.
Repeated k-Fold and Additional Considerations
Repeated k-fold runs the whole k-fold process several times with different random splits. It reduces the variance of the estimate and is often useful for smaller datasets.
Other practical reminders:
- keep a final external test set if you use CV for model selection,
- perform preprocessing inside each training fold,
- use parallel computation when models are expensive,
- and remember that some ensemble methods already provide internal estimates such as out-of-bag error.
Summary
In this lesson we covered:
- Why a single split can be unreliable
- How k-fold cross-validation averages performance across folds
- When LOOCV is useful and when it is too expensive
- Why stratification matters for imbalanced classification
- Why time-series validation must respect chronology
- How repeated k-fold improves stability
Next: With the evaluation strategy in place, we can decide which features deserve to stay in the model.