Hyperparameter Tuning and Early Stopping
Parameters Versus Hyperparameters
A useful distinction:
- parameters are learned from the data during fitting,
- hyperparameters are chosen by the practitioner before or around fitting.
Examples of hyperparameters include tree depth, regularization strength, number of neighbors, or learning rate.
Grid Search and Random Search
Two common search strategies are:
- Grid search: evaluate every combination on a predefined grid
- Random search: sample promising combinations without covering the full grid
Grid search is systematic but can become expensive very quickly. Random search is often more efficient when only a few hyperparameters matter strongly.
Bayesian Optimization and AutoML
When the search space is large, we can move beyond blind search.
- Bayesian optimization uses past evaluations to decide where to search next.
- AutoML automates larger parts of the workflow, including model choice, preprocessing, and tuning.
These tools are helpful, but they do not replace good experimental hygiene. A tuned system can still overfit if the validation logic is weak.
Early Stopping
For iterative models, a strong practical regularizer is early stopping:
- monitor validation loss or validation score,
- stop training when improvement stalls,
- keep the parameter values from the best iteration.
This prevents a model from continuing past the point where it starts fitting noise instead of signal.
Pruning as Complexity Control
Tree models use an analogous idea through pruning. We fit a rich tree first, then trim back branches that do not justify their complexity.
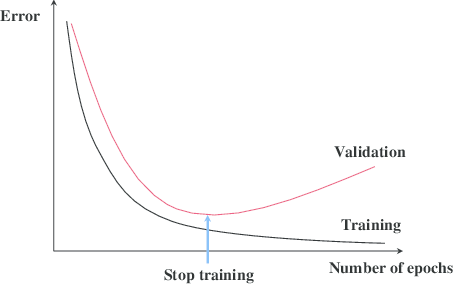
Whether the model is a neural network or a decision tree, the same principle applies:
complexity should be earned by validation performance, not by training performance alone.
A Reliable Tuning Workflow
A safe workflow usually looks like this:
- split the data cleanly,
- search hyperparameters on training/validation or cross-validation,
- lock the chosen settings,
- evaluate once on the untouched test set.
When data is limited, nested cross-validation can make this separation even safer.
Summary
In this lesson we covered:
- The difference between model parameters and hyperparameters
- Grid search and random search
- Bayesian optimization and AutoML
- Early stopping for iterative models
- Pruning as a validation-based form of complexity control
- The importance of a clean final evaluation after tuning
Next: Final lesson in this section: what changes when classes are rare and threshold choice becomes part of the model design.