Imbalanced Data and Threshold Selection
Why Imbalance Changes the Problem
When one class is rare, standard accuracy can become misleading. A model may predict the majority class almost all the time and still look good on paper.
That is why imbalanced classification often shifts attention toward:
- precision,
- recall,
- F1-score,
- ROC-AUC or PR-AUC,
- and threshold-dependent trade-offs.
Resampling Strategies
Common resampling options include:
- undersampling the majority class,
- oversampling the minority class,
- SMOTE, which synthesizes new minority examples rather than duplicating old ones.
Each option has a trade-off. Undersampling may discard useful information, while naive oversampling can overfit repeated cases.
Cost-Sensitive and Balanced Models
Sometimes it is better to keep the original data and change the learning objective instead.
Examples include:
- class weights in logistic regression or random forests,
- balanced random forests,
- boosting methods that emphasize hard or minority examples,
- ensembles designed specifically for imbalanced data.
These methods tell the model that some mistakes are more expensive than others.
Threshold Selection
Many classifiers output probabilities rather than final labels. The threshold used to convert score into class is therefore part of the modeling decision.
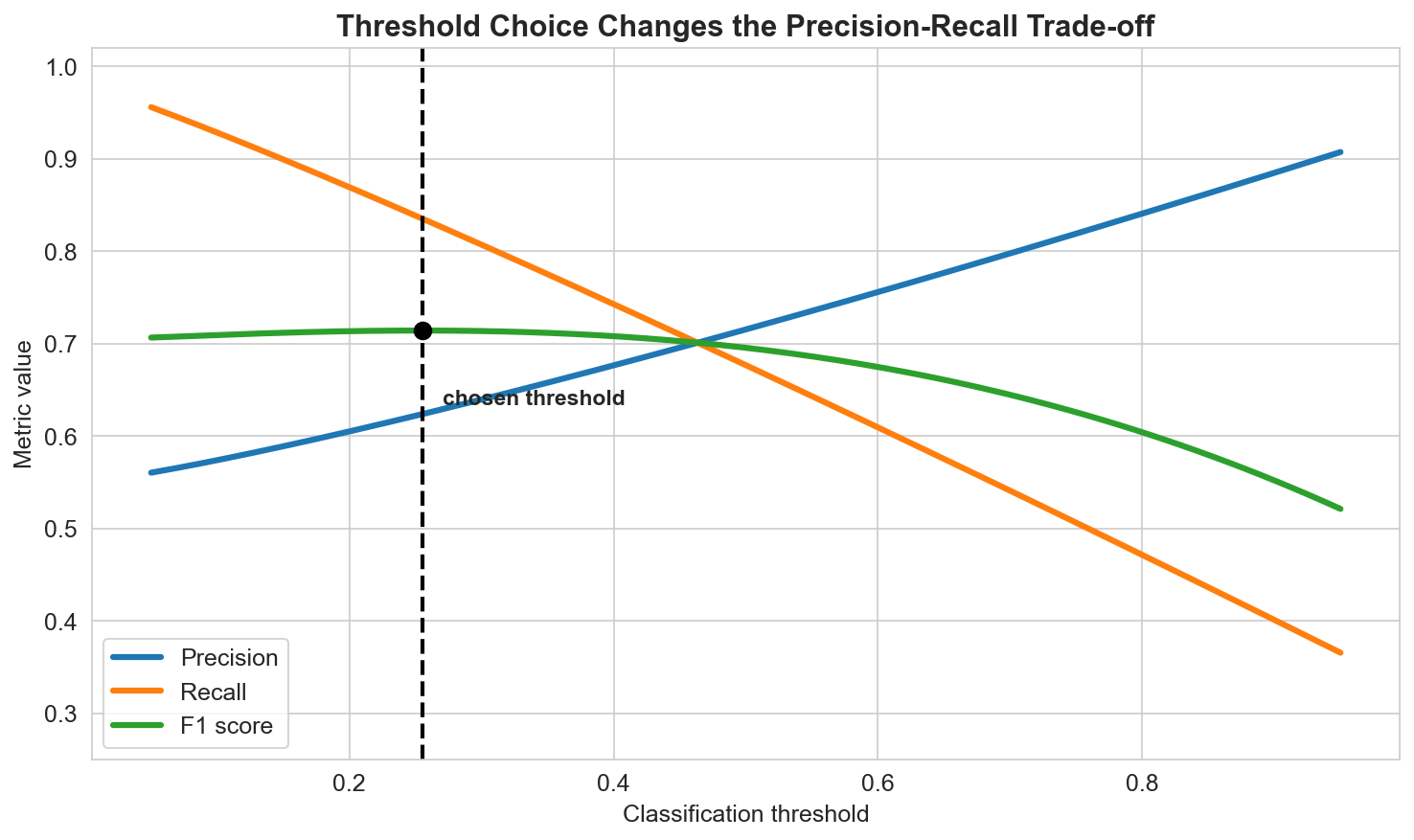
Lower thresholds usually increase recall and decrease precision. Higher thresholds often do the opposite.
The right threshold depends on the task:
- screening problems often prefer high recall,
- high-cost false alarms may require high precision,
- balanced situations may optimize F1 or a custom utility.
Data Augmentation
When training data is limited, augmentation can add useful diversity:
- image flips, crops, or rotations,
- text paraphrasing or replacement,
- time-series windowing or noise injection,
- synthetic minority generation such as SMOTE.
Augmentation is not a substitute for genuine data quality, but it can make models more robust when used carefully.
Summary
In this lesson we covered:
- Why accuracy is often insufficient on imbalanced data
- The main resampling strategies
- Cost-sensitive and ensemble-based approaches
- Why threshold choice changes practical performance
- How data augmentation can support robustness and balance
Next: We now move from supervised evaluation to unsupervised structure discovery with clustering methods.