Growth Control and Pruning
Why Fully Grown Trees Overfit
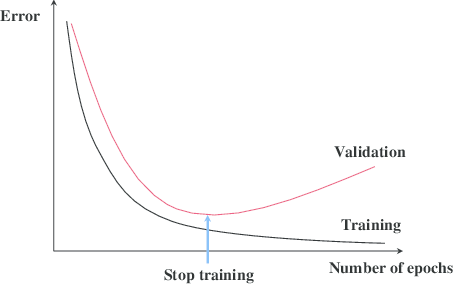
If we keep splitting until every leaf is pure, the tree can fit the training data almost perfectly. That usually sounds good, but it often means the model is learning noise rather than structure.
A very deep tree tends to have:
- low training error,
- high sensitivity to small data changes,
- and weaker generalization on new data.
Common Stopping Conditions
To keep a tree under control, we often stop growth when one of the following conditions is reached:
- Maximum depth: do not let the tree grow beyond a chosen depth.
- Minimum samples in a leaf: avoid leaves that contain too few observations.
- Minimum impurity improvement: require each split to improve node purity by a meaningful amount.
- Maximum number of leaves: cap the total number of terminal nodes.
- Pure node: stop when all remaining observations belong to one class.
These rules are forms of pre-pruning because they limit complexity before the tree is fully grown.
Pre-Pruning and Post-Pruning
There are two broad strategies for complexity control:
- Pre-pruning stops early using rules such as max depth or minimum samples per leaf.
- Post-pruning first grows a large tree, then trims back branches that do not help enough on validation data.
Pre-pruning is faster and simpler, but it can stop too early. Post-pruning is usually more reliable, but it costs more because the large tree must be trained first.
Cost-Complexity Pruning
A standard post-pruning strategy is cost-complexity pruning. For a subtree \(T\), we balance fit and size through
\[ \mathrm{Cost}(T) = \sum_{m=1}^{M_T} E(R_m) + \alpha |T|, \]where:
- \(E(R_m)\) is the leaf impurity or error,
- \(M_T\) is the number of leaves,
- \(|T|\) measures tree size,
- \(\alpha\) controls how strongly we penalize complexity.
As \(\alpha\) increases, simpler trees become more attractive.
In practice, the usual workflow is:
- grow a large tree,
- compute a sequence of candidate pruned trees,
- use cross-validation to choose the best \(\alpha\).
Computational Complexity and Practical Advice
The expensive part of tree building is the search over candidate splits. Naively scanning many thresholds for many features can be costly, especially on large datasets.
Common implementation tricks include:
- sorting values once per feature,
- evaluating candidate thresholds efficiently,
- and stopping early when a node becomes too small to matter.
Even with these optimizations, a single tree remains a high-variance model. That is why ensembles such as random forests and gradient boosting often outperform one tree while keeping the same core split logic.
Summary
In this lesson we covered:
- Why deep trees overfit easily
- The most common stopping conditions used in practice
- The difference between pre-pruning and post-pruning
- The cost-complexity pruning objective
- Why efficient split search matters for large datasets
- Why tree ensembles build directly on these ideas
Next: The next section zooms out from one model family and asks a broader question: how do we know whether any model is actually good?